


Was ist OPC UA?
OPC UA ist ein interoperabler und plattformunabhängiger Datenaustauschstandard. Dieser erfreut sich als Ergebnis der Kombination von etablierten Kommunikationstechnologien mit Informationsmodellen zu Recht großer Beliebtheit und weit verbreiteter Anwendung in der Industrie. Die Spezifikation ist öffentlich zugänglich und bietet Programmierern und Modellierern die notwendigen Grundlagen und Detailinformationen für den erfolgreichen Einsatz von OPC UA. Als Ergebnis erhält man eine einheitliche Schnittstelle, welche sowohl von Maschinenservern oder auf Microcontrollern als auch von reinen Softwareprodukten implementiert wird. Letztlich werden auch die übermittelten Informationen in für den Menschen verständlicher Form modelliert. Diese Einheitlichkeit sorgt im Vergleich zur Nutzung von maschinenspezifischen, proprietären Schnittstellen für einen deutlich geringeren Integrations- und Wartungsaufwand.
Mangelnde Übersicht und schwierige Informationsgewinnung
Wer sich jedoch frisch mit OPC UA beschäftigt, wird erstmal angesichts der rund 2000 Seiten Core-Spezifikation überfordert sein. Dazu kommen noch knapp 100 Standardisierungsdokumente domänenspezifischer Erweiterungen, die sogenannten Companion Specifications (CS). Aber selbst fortgeschrittene Nutzer wissen nicht alles und müssen immer wieder die Dokumente durchsuchen. Die OPC Foundation stellt dazu die Spezifikationen unter OPC UA Online Reference auch frei einseh- und durchsuchbar bereit. Jeder, der diese Funktion schon einmal genutzt hat, wird festgestellt haben, dass die Suchergebnisse von stark schwankender Qualität sind. Außerdem liefern sie meist nicht die gewünschten Informationen. Dies wird auch durch Feedback von OPC-UA-Modellierern belegt, die für ihr jeweiliges Unternehmen die Informationsmodelle erstellen und sich über die Standardkonformität und die Kompatibilität ihrer Modelle Gedanken machen müssen. Ich selbst nutze die References regelmäßig, da das Durchsuchen des Standards in PDF-Form noch deutlich größere Hürden aufweist und es sonst einfach nichts Besseres gibt.
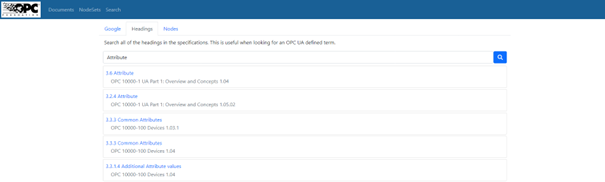
Negativbeispiel: Suche nach den „Attributes“
Nehmen wir ein einfaches, allgemeines Beispiel: Ich möchte eine Übersicht aller OPC UA Attributes (dazu gehören unter anderem die NodeId, der BrowseName und die Description) inklusive Definition oder Beschreibung der einzelnen Elemente haben. Standardmäßig ist in den References die Heading-Suche ausgewählt. Zusätzlich kann man direkt nach Nodes (die Informationsmodelle sind graphbasiert) suchen oder als dritte Variante die eingebettete Google-Suche bemühen. Belassen wir es bei der Überschriftensuche und suchen nach „Attribute“. Nach Verweisen auf allgemeine Begriffsdefinitionen und weiteren irrelevanten Ergebnissen aus verschiedensten CS steht das erste tatsächlich verwertbare Suchergebnis an Stelle Nummer 83(!). Auch das ist nicht optimal. Aber letztendlich kann man sich von dort über die Kapitelstruktur weiternavigieren, bis wir zu guter Letzt im Kapitel 5.2 von Part 3: Address Space Model die gesuchten Definitionen von DisplayName, WriteMask und Co. finden – welch eine Odyssee.
Die Lösung: eine semantische Suche
Was helfen würde ist eine Suche, die versteht, was der Nutzer wirklich will. Die nicht nur die Strings der Überschriften mit dem Suchbegriff vergleicht, sondern auch das Konzept dahinter. Teil des erst neulich gestarteten Forschungsprojekts „Clean OPC UA Information Modeling“ (CLOU) ist die Entwicklung einer solchen „semantischen Suche“. Technische Grundlage dessen ist ein Large Language Model (LLM), welches das entsprechende Sprachverständnis mitbringt. Die OPC-UA-Spezifikationen, sowohl Core als auch die CS, sowie Bücher, Webseiten und andere Dokumente werden in kleine Abschnitte aufgeteilt und inkl. Metadaten (Titel, Link, Buchseite) abgespeichert. Diese Daten dienen als Kontext für den LLM-Prompt, um sowohl die Frage zu beantworten als auch die entsprechende Quelle zurückzugeben. So kann der Benutzer/Benutzerin sie im Original nachlesen.
Doch es sollen nicht nur die Spezifikationen nach bestimmten Begriffen oder Konzepten durchsuchbar gemacht werden, sondern auch Nodesets der CS. Diese liegen beispielsweise in der UA Cloud Library und können ebenso so in kleine Stücke unterteilt und als Input für das LLM verwendet werden. Im Zusammenspiel mit den Dokumenten können dann auch Fragen zur Modellierung à la „Ich habe xy und möchte den Aspekt z abbilden, welche ObjectTypes kann ich dafür verwenden?“ beantworten. Dies führt zu einer einfacheren Informationsmodellierung, da die Anwender nicht mehr genaue Kenntnis über alle CS haben müssen. Durch die Wiederverwendung bereits bestehender Typen anstelle einer Neumodellierung verbessert sich im Allgemeinen die Semantik und damit die Interoperabilität verschiedener Modelle, ganz zu schweigen vom geringeren Entwicklungsaufwand.
Wie kann ich die Suche benutzen?
Die Semantische Suche als Teil des Projekts „CLOU“ befindet sich zurzeit in der Entwicklung und wird anschließend als Open Source zur freien Weiterverwendung veröffentlicht. Also schauen Sie in etwa einem Jahr gerne mal wieder in diesen Blogbeitrag, dann finden Sie hier einen Link zum Repository 😉. Bis dahin und im Allgemeinen unterstützen wir Sie mit dem OPC UA Lab gern persönlich bei Ihren spezifischen Herausforderungen mit OPC UA in Ihrem Unternehmen, von Beratung über Modellierung bis hin zur Softwareentwicklung. Schauen Sie bei Interesse auch gern auf der Projektwebseite von CLOU vorbei.
Für konkrete Rück- oder Anfragen steht Ihnen Christian Keilig unter den angegeben Kontaktdaten oder der Abteilungsleiter Herr Dr. Ken Wenzel sehr gerne über ken.wenzel@iwu.fraunhofer.de zur Verfügung.
Headerbild: © Pixabay
Autor: Christian Keilig



